DataFrame Basics
What is a DataFrame?
In TinyFrameJS, DataFrame is a convenient wrapper around the core data structure TinyFrame. DataFrame provides a rich API for working with tabular data, while TinyFrame ensures efficient storage and processing of data at a low level.
TinyFrame uses TypedArray (such as Float64Array and Int32Array) for storing data in a dense, column-oriented format, which provides a significant performance advantage compared to regular JavaScript arrays and objects.
Architecture of Data in TinyFrameJS
TinyFrame: The Foundation of Performance
TinyFrame is an internal data structure that:
- Stores data in columnar format using TypedArray
- Provides dense memory layout and type uniformity
- Enables 10-100× performance gains compared to traditional JS objects and arrays
- Is optimized for fast operations on large datasets
// Internal TinyFrame structure (not intended for direct use)
{
columns: {
date: ['2023-01-01', '2023-01-02', ...],
price: Float64Array([100, 105, ...]),
volume: Float64Array([1000, 1500, ...])
},
index: Int32Array([0, 1, 2, ...])
}
DataFrame: Convenient API
DataFrame is a class that:
- Wraps TinyFrame, providing a convenient API
- Is automatically extended with methods during initialization
- Supports method chaining
- Provides an intuitive interface for working with data
Under the Hood
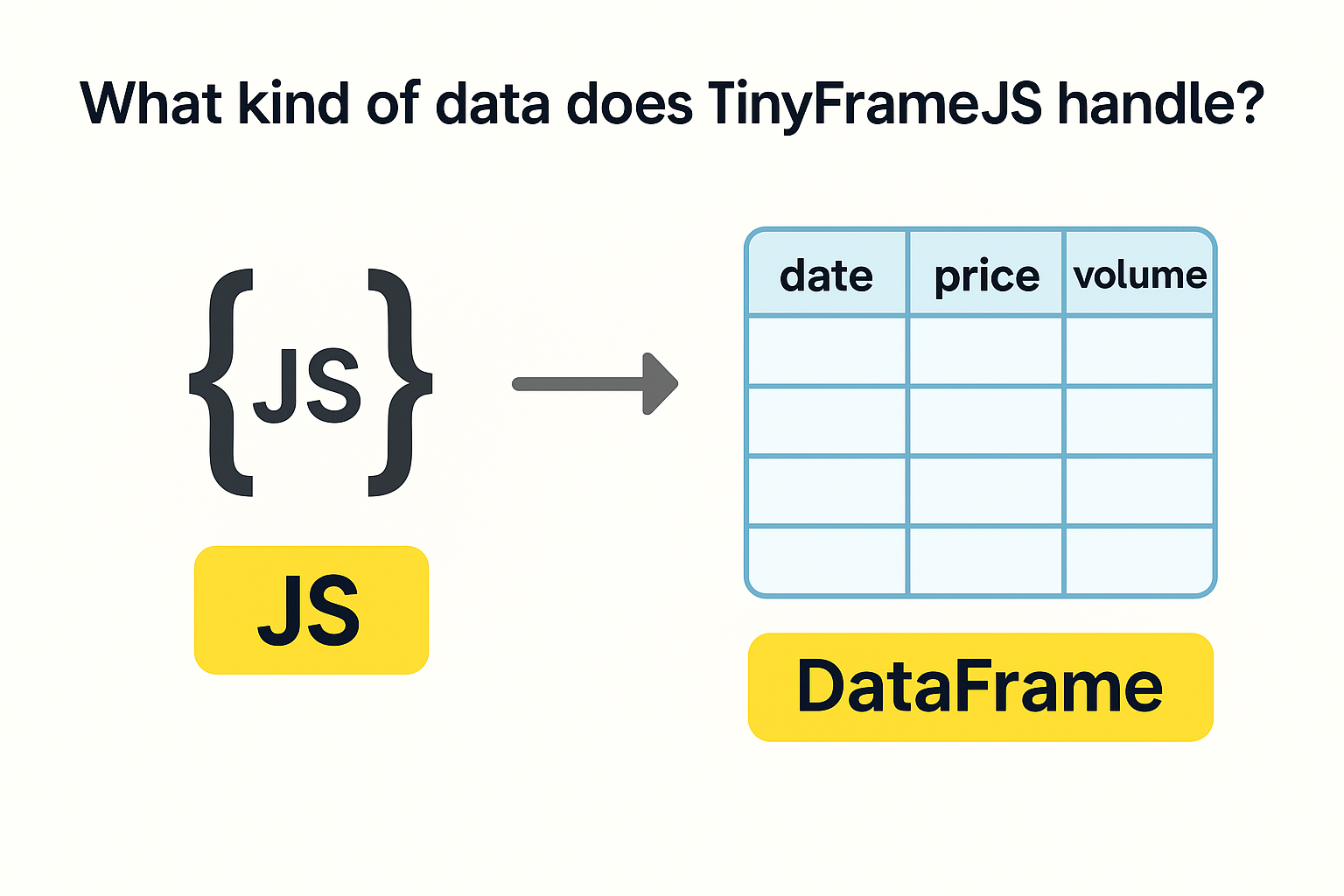
Each column is its own TypedArray. Rows are simply indices 0…N-1.
Creating a DataFrame
For creating a DataFrame, it's recommended to use the static method DataFrame.create(), which internally calls the createFrame function to create an optimized TinyFrame structure:
import { DataFrame } from 'tinyframejs';
// Recommended way to create a DataFrame
const df = DataFrame.create({
date: ['2023-01-01', '2023-01-02'],
price: [100, 105],
volume: [1000, 1500]
});
// Alternative way (uses the same mechanism internally)
const df2 = new DataFrame({
date: ['2023-01-01', '2023-01-02'],
price: [100, 105],
volume: [1000, 1500]
});
// Display the DataFrame
df.print();
Output:
┌───────┬────────────┬───────┬────────┐
│ index │ date │ price │ volume │
├───────┼────────────┼───────┼────────┤
│ 0 │ 2023-01-01 │ 100 │ 1000 │
│ 1 │ 2023-01-02 │ 105 │ 1500 │
└───────┴────────────┴───────┴────────┘
You can also create a DataFrame from an array of objects:
const df3 = DataFrame.create([
{date: '2023-01-01', price: 100, volume: 1000},
{date: '2023-01-02', price: 105, volume: 1500}
]);
Types of DataFrame Methods
DataFrame methods fall into two categories:
1. Transformation Methods
These methods create a new DataFrame and can be chained together:
const filteredSorted = df
.dropNaN('price') // Removes rows with NaN in the price column
.sort('price') // Sorts by the price column
.head(10); // Takes the first 10 rows
2. Aggregation Methods
These methods return a scalar value or array and typically end a method chain:
const averagePrice = df
.dropNaN('price')
.mean('price'); // Returns a number (average value)
const summary = df.describe(); // Returns an object with descriptive statistics
Automatic Extension Mechanism
One of the key innovations of TinyFrameJS is the automatic method extension:
- All methods are defined as pure, curried functions with dependency injection
- The
inject.jsmodule centralizes dependencies such as validators - The
autoExtend.jsmodule automatically attaches all methods toDataFrame.prototype - This happens once during initialization at runtime
This approach provides several benefits:
- Zero boilerplate: No need for manual method registration
- Clean separation: Clear separation between core logic and API
- Flexibility: Methods can be easily added, removed, or modified
- Optimization: Support for tree-shaking to reduce bundle size
Data Flow
TinyFrameJS follows a clear data flow from raw inputs to flexible API:
Raw data (CSV, JSON, API) → reader.js → createFrame.js →
TinyFrame → DataFrame → Automatically extended methods →
User API: df.sort().dropNaN().head().count()
Usage Examples
Basic Operations
// Getting information about the DataFrame
console.log(df.columns); // List of columns
console.log(df.rowCount); // Number of rows
// Converting to an array
const array = df.toArray(); // Converts to an array of objects
// Accessing data
const firstRow = df.row(0);
const priceColumn = df.column('price');
Table Display and Formatting
// Basic table display
df.print(); // Prints the DataFrame in a formatted table
// Output:
// ┌───────┬────────────┬───────┬────────┐
// │ index │ date │ price │ volume │
// ├───────┼────────────┼───────┼────────┤
// │ 0 │ 2023-01-01 │ 100 │ 1000 │
// │ 1 │ 2023-01-02 │ 105 │ 1500 │
// └───────┴────────────┴───────┴────────┘
// Customized table display with options
df.print({
maxRows: 10, // Maximum number of rows to display
maxCols: 5, // Maximum number of columns to display
precision: 2, // Number of decimal places for floating-point numbers
truncate: 20, // Maximum length of string values before truncation
header: true, // Whether to display the header
index: true, // Whether to display the index
border: 'rounded' // Border style: 'rounded', 'sharp', or 'none'
});
// HTML table for web display
const htmlTable = df.toHTML({
classes: ['data-table', 'striped'],
id: 'my-table',
caption: 'Stock Prices'
});
console.log(htmlTable);
// Markdown table for documentation
const mdTable = df.toMarkdown();
console.log(mdTable);
// ASCII table for console output (without Unicode characters)
df.print({ border: 'ascii' });
// Output:
// +-------+------------+-------+--------+
// | index | date | price | volume |
// +-------+------------+-------+--------+
// | 0 | 2023-01-01 | 100 | 1000 |
// | 1 | 2023-01-02 | 105 | 1500 |
// +-------+------------+-------+--------+
// Colored table output (in supported terminals)
df.print({
colorize: true,
headerStyle: 'bold',
negativeStyle: 'red',
positiveStyle: 'green'
});
// Table with summary statistics at the bottom
df.printSummary();
// Table with pagination for large DataFrames
df.printPaged(10); // 10 rows per page
Transformations and Aggregations
// Chain of transformations and aggregation
const result = df
.sort('price') // transformation → returns a new DataFrame
.dropNaN('volume') // transformation → returns a new DataFrame
.head(10) // transformation → returns a new DataFrame
.mean('price'); // aggregation → returns a number
Group Operations
const grouped = df.groupBy(['sector']).aggregate({
price: 'mean',
volume: 'sum'
});
Reshaping Operations
df.pivot('date', 'symbol', 'price');
df.melt(['date'], ['price', 'volume']);
Working with Tables
Joining Tables
// Create two DataFrames
const customers = DataFrame.create([
{ customer_id: 1, name: 'John', country: 'USA' },
{ customer_id: 2, name: 'Alice', country: 'Canada' },
{ customer_id: 3, name: 'Bob', country: 'UK' }
]);
const orders = DataFrame.create([
{ order_id: 101, customer_id: 1, amount: 200 },
{ order_id: 102, customer_id: 2, amount: 150 },
{ order_id: 103, customer_id: 1, amount: 300 },
{ order_id: 104, customer_id: 3, amount: 250 },
{ order_id: 105, customer_id: 2, amount: 100 }
]);
// Inner join
const innerJoin = customers.join(orders, 'customer_id');
innerJoin.print();
// Left join
const leftJoin = customers.join(orders, 'customer_id', { how: 'left' });
leftJoin.print();
// Calculate total orders per customer
const customerOrders = leftJoin
.groupBy('customer_id')
.aggregate({
name: 'first',
country: 'first',
amount: 'sum'
})
.rename({ amount: 'total_amount' });
customerOrders.print();
Handling Missing Values
// Create a DataFrame with missing values
const dfWithNaN = DataFrame.create({
product: ['Apple', 'Orange', 'Banana', 'Mango', null],
price: [1.2, 0.9, 0.5, null, 1.5],
quantity: [10, 15, null, 7, 9]
});
// Check for missing values
console.log(dfWithNaN.isNaN().sum()); // Count NaN values in each column
// Fill missing values
const filled = dfWithNaN
.fillNaN('product', 'Unknown') // Fill missing products with 'Unknown'
.fillNaN('price', dfWithNaN.mean('price')) // Fill missing prices with mean
.fillNaN('quantity', 0); // Fill missing quantities with 0
filled.print();
// Drop rows with any missing values
const cleanDf = dfWithNaN.dropNaN();
cleanDf.print();
// Drop rows with missing values only in specific columns
const partialClean = dfWithNaN.dropNaN('price');
partialClean.print();
Time Series Operations
// Create a time series DataFrame
const timeSeries = DataFrame.create({
date: [
'2023-01-01', '2023-01-02', '2023-01-03',
'2023-01-04', '2023-01-05', '2023-01-06'
],
value: [100, 105, 98, 103, 110, 115]
});
// Convert string dates to Date objects
const tsWithDates = timeSeries.assign({
date: row => new Date(row.date)
});
// Sort by date
const sortedTs = tsWithDates.sort('date');
// Calculate rolling average (window of 3)
const rollingAvg = sortedTs.rolling('value', 3, 'mean');
rollingAvg.print();
// Calculate percentage change
const pctChange = sortedTs.assign({
pct_change: (row, i, df) => {
if (i === 0) return 0;
const prevValue = df.row(i-1).value;
return ((row.value - prevValue) / prevValue) * 100;
}
});
pctChange.print();
// Resample daily data to 3-day periods
const resampled = sortedTs.resample('date', '3d', {
value: 'mean'
});
resampled.print();
Data Export and Visualization
// Export to different formats
const jsonStr = df.toJSON();
const csvStr = df.toCSV();
// Save to file (if in Node.js environment)
df.toCSV('data.csv');
df.toJSON('data.json');
// Basic visualization
df.plot.bar('category', 'value');
df.plot.line('date', 'value');
df.plot.scatter('x', 'y');
df.plot.histogram('value', { bins: 10 });
// More complex visualization with options
df.plot.bar('category', 'value', {
title: 'Sales by Category',
xLabel: 'Product Category',
yLabel: 'Sales Amount',
color: 'steelblue',
width: 800,
height: 400
});
Future Extensions
TinyFrameJS plans to include several performance-oriented extensions:
StreamingFrame
For processing massive datasets that don't fit in memory:
- Batch processing of large files
- Streaming API for continuous data input
- Efficient memory usage for datasets with 10M+ rows
LazyPipeline
For optimized execution of complex transformations:
- Deferred execution until results are needed
- Automatic merging and optimization of operations
- Reduction of intermediate memory allocations
Advantages of TinyFrameJS
- High Performance: 10-100× faster than traditional JS objects and arrays
- Pure JavaScript: No binary dependencies (no WebAssembly or C++ required)
- Modular Design: Support for tree-shaking to optimize bundle size
- Automatic Extension: No need for manual method registration
- Flexible API: Methods can be chained together to create complex transformations
Comparison with Regular JS Code
| Regular Arrays & Objects | TinyFrameJS | |
|---|---|---|
| Complexity | for + reduce | Declarative API |
| Memory | Sparse objects | Dense Float64Array |
| Speed | ~~ slow ~~ | C-like fast access |
| Chaining | — | .sort().head().mean() |
Next Steps
Now that you understand the basics of DataFrames in TinyFrameJS, you can:
- Learn how to read and write tabular data
- Explore more advanced filtering and selection techniques
- Discover how to create plots from your data
- Learn about derived columns and calculations
- View the complete package overview
See Also
- API Reference — detailed description of all methods
- Benchmark results — comparison with Pandas, Danfo.js, Arquero
- Roadmap — StreamingFrame, LazyPipeline and WebAssembly acceleration